Coding agent frameworks
After reading How to Build an Agent (or: The Emperor Has No Clothes), I thought that building a coding agent was surprisingly straightforward. The article describes it as mostly just a matter of function calling and describing those functions clearly in the prompt. But I wanted to go deeper: what do state-of-the-art coding agents look like in practice? Multi-SWE-bench, a recent paper from ByteDance, evaluates three modern approaches: Agentless, SWE-agent, and OpenHands. In this post, I will walk through each of these frameworks. Let’s see if the emperor manages to get dressed.
By the way, if you're looking for definitions, this is probably the best definition of an agent: "Agents are models using tools in a loop".
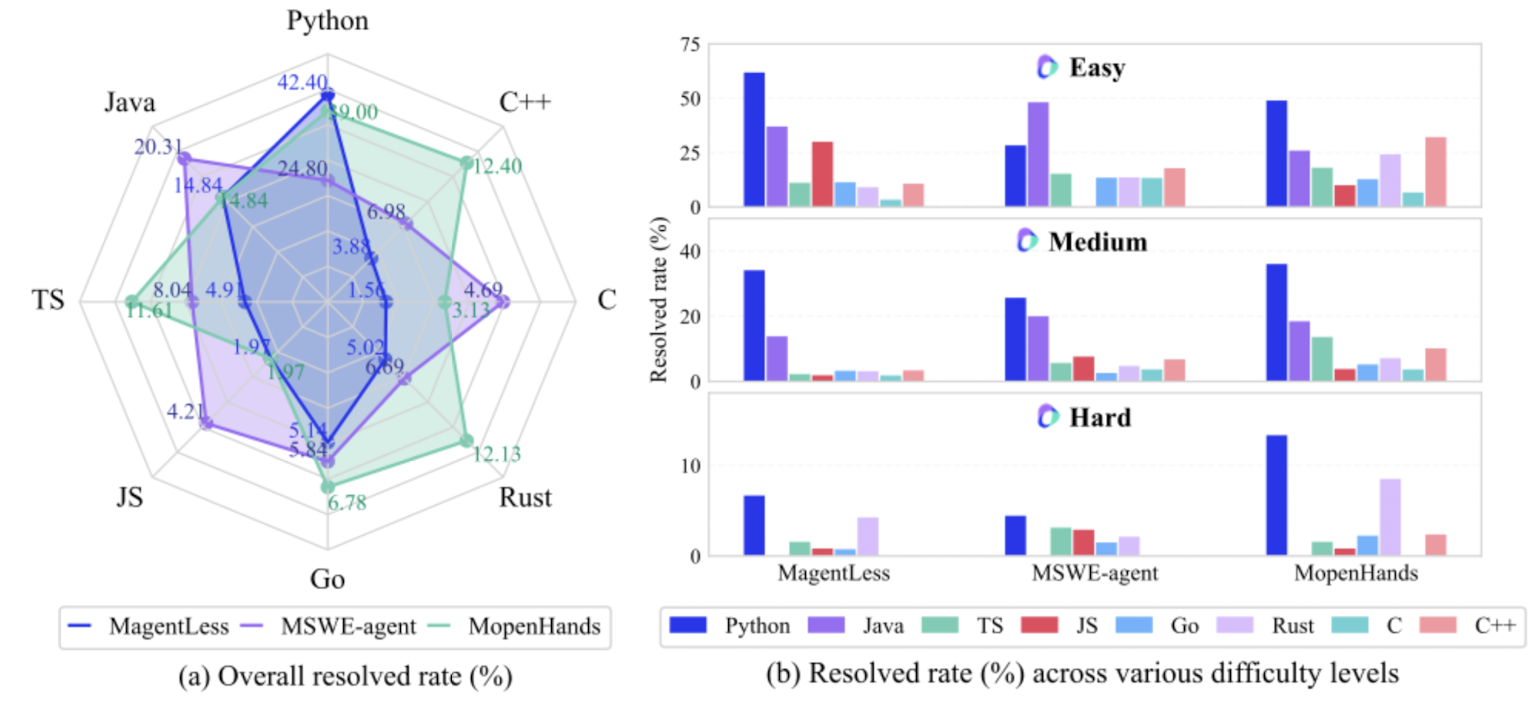
Multi-SWE-bench is a highly readable paper with many interesting insights about the performance of language models when it comes to resolving GitHub issues. The paper shows that SOTA methods that do well on the standard SWE-bench (which contains just Python problems), perform much worse on resolving issues in other languages. Based on an extensive evaluation, it shows how the resolved rate falls steeply from easy (< 15 min human fix) to hard (> 1 h) issues; on hard tasks, most LLM/agent pairs approach 0 % success. These results are somewhat different to what e.g. METR published; it indicates that the intelligence of LLMs is still very jagged.
Agentless
Agentless: Demystifying LLM-based Software Engineering Agents, published in July 2024 by the University of Illinois, proposes an 'agentless' approach to resolving dev issues. Their setup was adopted by OpenAI as the go-to coding framework for o1, because they were the best-performing open-source scaffolding framework at the time. As the name suggests, this framework shines because of its simplicity; there is no function calling at all. They give three reasons for this:
- Tool use is just complex for LLMs; they can easily make mistakes calling a function, which reduces performance as the erroneous output is then used again to guide the next step.
- The large action space of options when using agents can make it easy to decide on the wrong task to perform, which causes the agents to perform sub-optimal explorations.
- Self-reflection of current models is limited; they do not filter out what is correct, irrelevant, incorrect, or misleading information.
Note: the above looks true, although it also looks like something models can easily get better at with more tuning! Teach models to reflect more often with specific instruction data, instruct them to check function definitions before calling them, and one should be able to make good improvements (1 and 3 will be improved). Improving the decision-making process given a large action space might be more difficult, particularly in situations where a standard approach will not work.
Based on the above, they propose an 'agentless' framework consisting of three steps: localisation, repair, and patch validation. The process is agentless as it avoids using an autonomous, multi-turn LLM “agent” that plans actions, executes tools, and reacts based on environment feedback. The tools (such as reading, editing, etc.) are hardcoded parts of the pipeline, and are not freely available to an agent.
Localisation of relevant code
Localisation is done in three steps: first, relevant files are localised, then relevant elements within these files are localised, and finally, edit locations are determined.
1. Localise relevant files
The input for the LLM to perform this step is a tree-like representation of a repository along with the issue description and the request to list the top N suspicious files that need further inspection or modification to resolve the issue. In addition to that, an embedding-based retrieval method is used. This works as follows: we first ask the LLM to produce a list of irrelevant folders that do not need to be further inspected. Then, we divide the remaining files into chunks of code segments and compute their embedding using an embedding model. We then embed the original issue description and compute the cosine similarity between the issue embedding and each chunk to retrieve a list of relevant files. We then combine the results of both the prompting and embedding-based method, resulting in a final list of relevant files.
2. Localise to related elements
Now that we have a list of relevant files, we want to find the relevant elements within these files. Assuming we are limited by a limited context length, we cannot just add all files to the context. So instead, we add a compressed skeleton format of each file, containing the list of classes, functions and variable declarations. With this context, we ask the LLM to provide a list of related classes and functions.

3. Localise to edit locations
Now that we have relevant elements, potentially from different files, we ask the LLM to provide the final set of edit locations, specified by line numbers, functions or classes. The input of relevant elements obtained already is small, so we can simply add this to our context and prompt the model. Straightforward enough.
Create the patch to fix the issue
Now that we have our edit locations, we want to produce the correct code to solve the issue at hand. To give the LLM the relevant information, we add the code surrounding the edit locations to our context, and then ask it to generate patches to solve the issue. Specifically, the LLM is asked to generate a search/replace edit: a diff format:
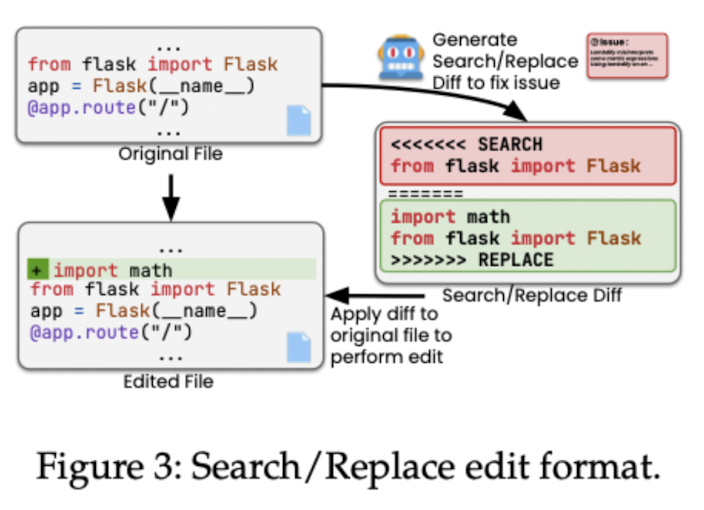 The diff format avoids generating the complete code but focuses instead on small edits. This is more cost-efficient, and more reliable as there are fewer chances to hallucinate. Agentless asks the LLM to produce multiple (40) candidate patches per issue.
The diff format avoids generating the complete code but focuses instead on small edits. This is more cost-efficient, and more reliable as there are fewer chances to hallucinate. Agentless asks the LLM to produce multiple (40) candidate patches per issue.
Patch validation
In this step, we finally execute some code. Because we have multiple patch candidates, we want to validate which one works. We cannot rely on bug-triggering tests -- these are not available in a realistic scenario where we just have a user reporting a bug without concrete tests to reproduce it. Fortunately, we can usually generate these tests! Again, we generate multiple (40) tests, normalise them (remove spaces and comments, normalise test names), and keep the tests that are most frequently occurring.
Now, before we run the newly generated tests, we want to make sure that other tests are passing. So we run all other tests, but ask the LLM to exclude the tests that should not be ran if the issue has been correctly fixed (as they might fail as we change the issue). To me, this initially seems somewhat counterintuitive as excluding tests related to the issue might remove the ability to test current, desired behaviour related to the issue. I guess the idea is that because we generated tests for the issue, we should not rely on older tests that were not able to catch whatever was mentioned in the issue report; and these tests could in fact enforce/test the wrong behaviour.
Now, to select the relevant patch, we run all tests and keep the patch with the lowest number of regression failures. We then run the newly created tests and again only keep the patches that pass these tests. If no patch can pass these new tests, we only use the regression tests to select the patch. If multiple tests pass all tests, we normalise the code (remove comments/spaces/newlines) and keep the patch that has the most amount of counts among the normalised patches (I guess we can assume that after normalisation some candidates are the same).
And that's it! It's a relatively simple approach, but with many generated candidate tests and patches. However, it seems to work well; this setup obtains 32% on SWE-bench Lite with GPT-4o (gpt-4o-2024-05-13), which was the state of the art for open-source tools in 2024.
SWE-Agent
SWE-Agent, published in May 2024 by Princeton University, does use a more agentic framework. Their approach with GPT-4 Turbo leads to a 12.4% accuracy on SWE-bench.
Note: this is not the SWE-bench Lite version evaluated by Agentless. Although the Lite version is reportedly designed with a 'similar difficulty spectrum', it focuses on more self-contained bugs, which should make it easier compared to the full dataset?
SWE-Agent uses an agent-computer interface (ACI), which means that they use an additional LLM that can perform certain actions, such as viewing, searching or editing files. To create the right context for the ACI, they manually inspect its behaviour and run a grid search to select the best ACI configuration. Given this analysis, they come up with the following guidelines:
- Actions should be simple and easy to understand for agents. Commands with many options are confusing.
- Actions should be compact and efficient; important actions such as file navigation or editing should be consolidated into as few actions as possible.
- Environment feedback should be informative but concise.
- Guardrails mitigate error propagation and hasten recovery. For example, code syntax checks to automatically detect mistakes can help agents recognise and correct errors.
Now, what can the agent do? Let's describe the given functions. For each function, the agent generates a thought and a command, and then incorporates the feedback form the command's execution in the environment. The following actions are possible:
- Search and navigation. SWE-agent doesn't just give the agent access to all Linux tools related to this, but defines their own functions, with the goal to suppress verbose results. For example, the search command returns at most 50 results; and if there are more than 50 results, the suggestion to the agent is to be more specific.
- File viewer. The agent can open at most 100 lines of a file at a time, and can use commands
scroll_downandscroll_up, or access a specific line with thegotocommand. To guide the agent, these commands display the full path to open the file, the number of lines in the file, number of lines omitted before and after the current window, and the file line numbers. - File editing. Given a start line, end line and replacement text, this command edits files. The command outputs the updated content of the file and results of a code linter to allow the agent to observe the effect of the change. If there are linting errors, the file edit is discarded.
- Context management. The overall process is guided by a context management setup, with a system prompt instructing the agent to generate both a thought and an action. If an action triggers an error, the agent is encouraged to try again until a valid generation is received. Once an action is done successfully, all error messages except for the first one are removed from the prompt. If a command does not return anything, the message 'Your command ran successfully and did not produce any output' is included in the response. To limit the context length, outputs that are older than the last 5 commands are collapsed into a single line.
In addition to these specific commands, the agent also has access to common Linux commands.
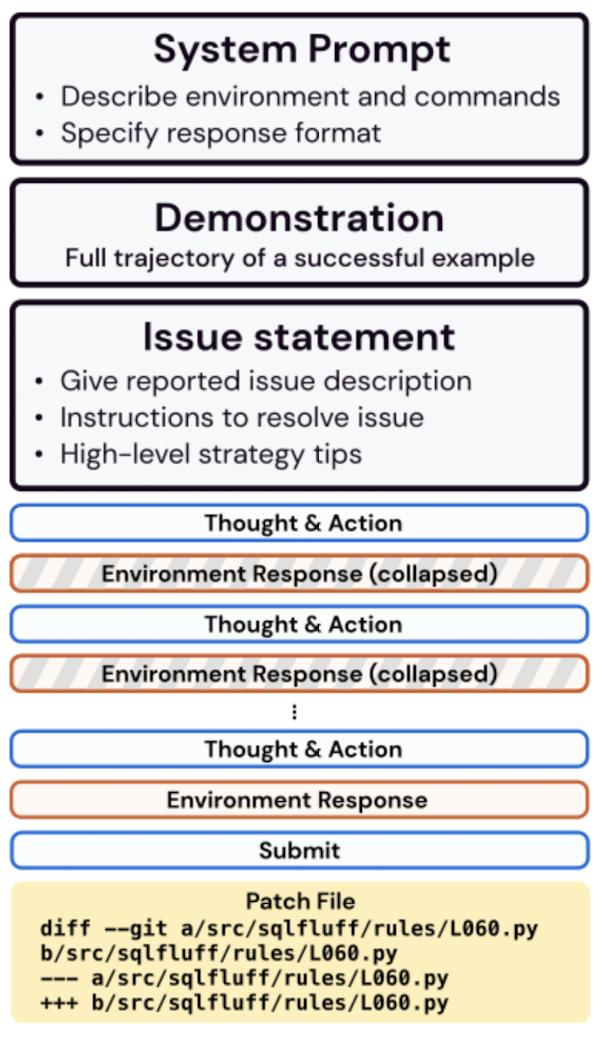
Findings
File editing is difficult. The file editing scaffolding is critical -- without it (but with e.g. sed for editing files), performance drops by 7.7 percentage points. Without the linting feedback, and the process of discarding edits in case of linting errors, the performance drops by 3 percentage points. Regardless, editing remains challenging; 51.7% of the executed SWE-bench tasks had 1+ failed edit. As such, any attempt at editing has a 90.5% chance of eventually being successful, which drops to 57.2% after a single failed edit.
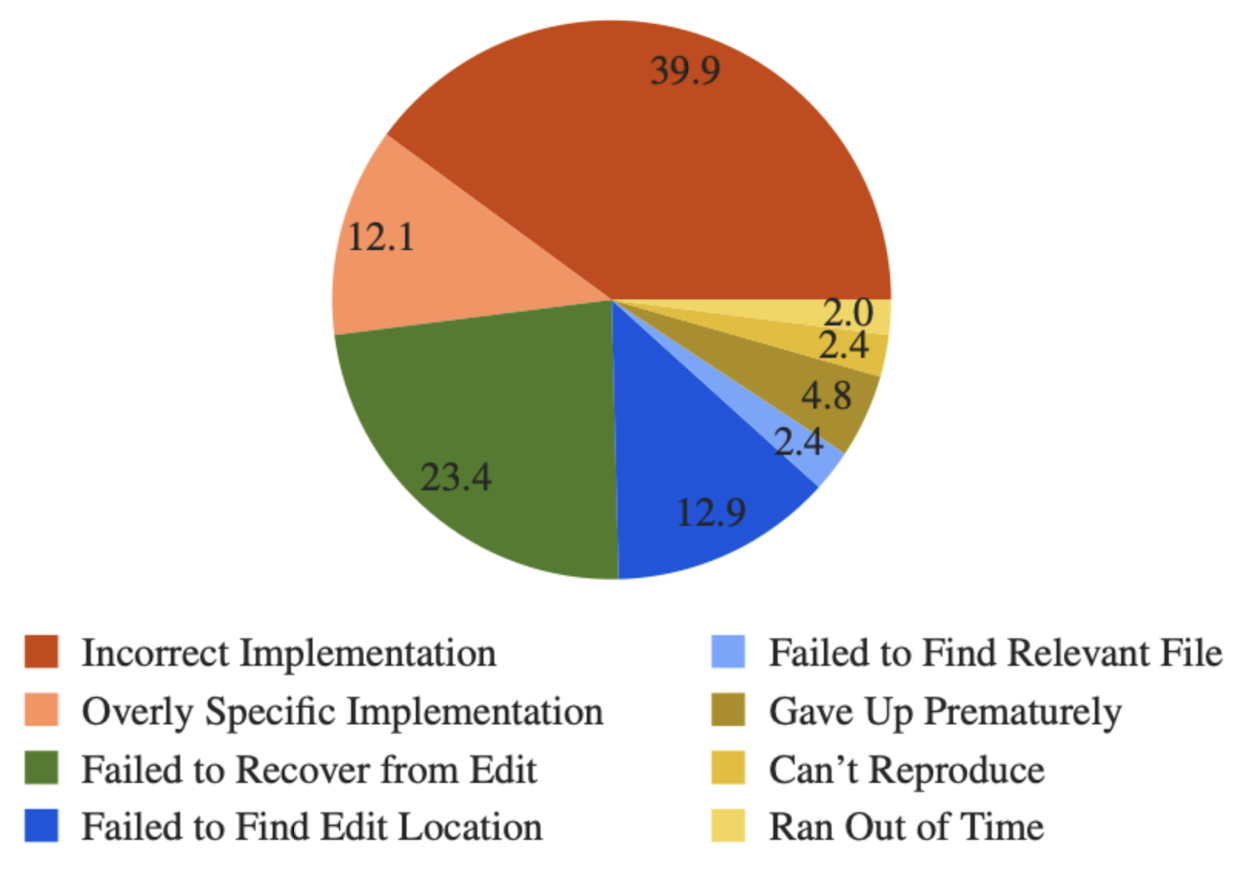
Most failures are incorrect implementations. See circle diagram below; these categorisations are made by GPT-4.
 Agents succeed quickly and fail slowly. Successful runs are completed earlier and at a cheaper cost than unsuccessful ones. 93% of the resolved instances are submitted before exhausting their cost budget. This suggests that increasing token or budget limits will likely not substantially improve performance. It looks like longer runs just increase the chance of making errors, resulting in a lower resolved rate.
Agents succeed quickly and fail slowly. Successful runs are completed earlier and at a cheaper cost than unsuccessful ones. 93% of the resolved instances are submitted before exhausting their cost budget. This suggests that increasing token or budget limits will likely not substantially improve performance. It looks like longer runs just increase the chance of making errors, resulting in a lower resolved rate.
OpenHands
OpenHands: An Open Platform for AI Software Developers as Generalist Agents, first published in July 2024, describes an open-source project that consists of a range of coding agent features such as multi-agent delegation, agent evaluation and more general interaction mechanisms. OpenHands focuses on creating a more general platform for 'digital agents' rather than optimising a setup for a specific task. As a result, the OpenHands paper is mostly a list describing available features (e.g. access to a Chromium brower, a Jupyter IPython environment, Docker image support, etc.) rather than a specification of how to best run an agent. Since listing features is not the purpose of this blog post, I'll refer to the paper if you want to know more. As OpenHands is more general, it might be less optimised for Python or SWE-bench, and therefore perform slightly better on other coding languages, as can be seen in the Multi-SWE-bench paper:
Final notes
Reading the papers, I had to think of this section from the Dwarkesh podcast with Trenton Bricken and Sholto Douglas where Sholto answers what limits model performance right now:
I think what we're seeing now is closer to: lack of context, lack of ability to do complex, very multi-file changes… sort of the scope of the task, in some respects. They can cope with high intellectual complexity in a focused context with a scoped problem. When something's a bit more amorphous or requires a lot of discovery and iteration with the environment, with this kind of stuff they struggle more. Maybe the way I would define the thing that's holding them back like this. If you can give it a good feedback loop for the thing that you want it to do, then it's pretty good at it. If you can't, then they struggle a bit.
Something similar can be seen in the papers summarised above: it is scoping the task (deciding on the right action) and many environment interactions where models are currently failing. Hence, all frameworks:
- Find ways to compress the context (improves context, simplifies scoping)
- Limit the model's action space significantly (simplifies scoping, limits iteration and discovery)
My current, maybe naive take is that scaling reinforcement learning on specific tasks will go a long way to resolve these issues. Even though Multi-SWE-bench shows limited progress in languages other than Python, the progress on SWE-bench is truly astounding - and this is, for as far as I can tell, mostly because of scaling RL; allowing the model to discover how to best take actions given an action space and environment. From this perspective, RL offers so much more than supervised training; it offers a way to discover the right actions; which seems to be a crucial component to fix current limitations. The environment of different coding languages varies in terms of tooling, runtime errors, memory management, but training with RL to deal with these variations should help. I suspect that as the community progresses on scaling RL, more and more of the structure included in current agent frameworks can be removed - the model will learn what to do when. For better generalisation, the key to progress may lie not in further refining heuristics, but in letting models learn through interaction what those heuristics should be.
If you liked this blog post, feel free to share it or follow me on LinkedIn or Twitter.