Research notes: Reframing computer vision as token prediction
This talk by Lucas Beyer has been making the rounds on X recently, and for good reason. It gives a sharp overview of the development of computer vision and vision-languag emodels over the past five years. I thought it would be useful to expand my notes into a post and highlight what stood out.
The overall theme of this talk is the idea that more and more computer vision tasks are reframed as token prediction with autoregressive objectives, where the hardest problem is now not the architecture design anymore, but designing data and objectives that make this reframing effective.
From ImageNet to CLIP
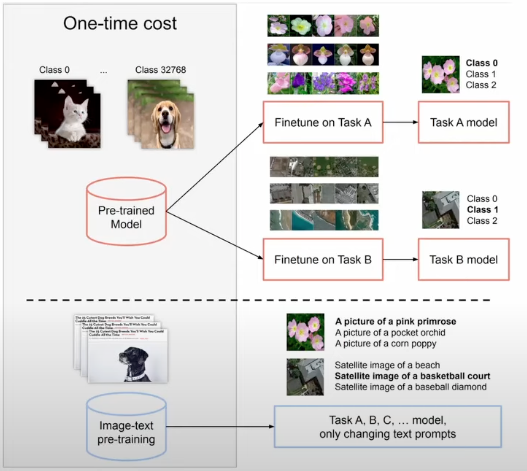
For much of the 2010s, training image models followed the following recipe: pre-train on ImageNet, then fine-tune for a specific downstream task. The scope of such models was limited by the dataset creator’s choices. ImageNet had just 1,000 categories. MS-COCO had 80: chosen after the dataset creators asked their children what everyday objects they could name. As a result, models really only knew about a specific subset of the world. This paradigm changed significantly with CLIP (2021) and ALIGN (2021). Instead of fixed label sets, these models pre-trained on noisy collections of image–text pairs scraped from the web. Now, models could recognise concepts beyond small, curated class lists. As a result, fine-tuning is not always needed anymore to do well on certain computer vision tasks (e.g. similarity search); you can just ask the model for the task you want, in natural language and find the images most similar to the embedded text description.
SigLIP: Scaling Contrastive Learning
CLIP’s loss function builds an similarity matrix of all image–text pairs in a batch of size , and applies a cross-entropy loss in both directions (image→text and text→image). For each row (or column), a softmax normalises similarities across all samples in the batch, resulting in scores between 0 and 1. This requires synchronisation across devices to aggregate all embeddings. Since the naive softmax is numerically unstable, implementations subtract the maximum logit per row/column before exponentiation, which requires an additional pass across the batch. This couples every example in the batch, creating synchronization overhead that grows as you scale up batch size or devices.
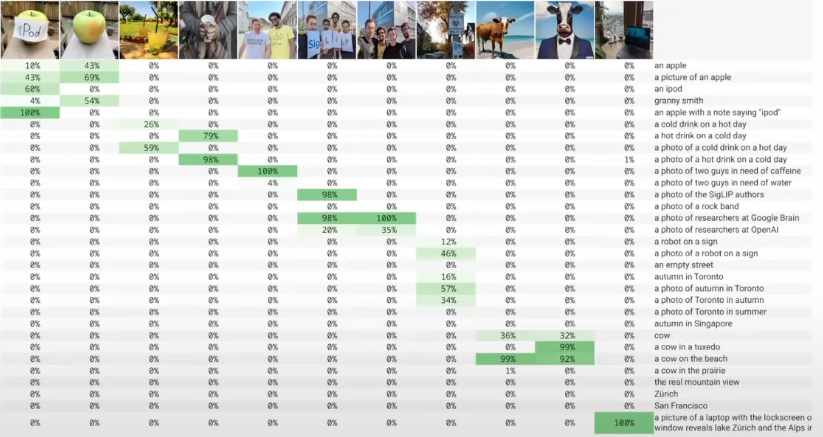
SigLIP (2023) simplifies contrastive training by replacing the batch-level softmax with a pairwise sigmoid cross-entropy loss. Instead of normalising similarities across the full similarity matrix, it treats each image–text pair independently as a binary classification problem (“do these match?”). This makes the loss pointwise, decoupling examples from one another. Without the need for global normalisation across rows and columns, training becomes more memory- and compute-efficient, and supports very large batch sizes (up to one million), leading to better models. Beyond scalability, SigLIP’s pairwise formulation makes the similarity scores learned during training more directly interpretable on a per-pair basis, since they are not normalized relative to other samples in the batch. This means you can probe how different captions (“cow” vs. “cow in a tuxedo on the beach”) change the predicted match score for the same image without that score being defined only in relation to other captions present in the batch. See below:
There is a multi-lingual version of SiGLIP as well.
CLIP/SigLIP forms now, together with DINO, the main paradigm to train image encoders.
CapPa: Captioning as Pre-Training
Contrastive methods like CLIP and SigLIP have one main limitation: to minimise the loss, the model only needs to latch onto the words that are discriminative within the mini-batch. If a batch contains one image of a cat and one of a dog, recognising “cat” and “dog” is sufficient. But for a caption such as “a cat sitting left of a dog”, things become more fragile. For the model to actually care about “sitting”, the batch would also need an image where the animals are standing. For “left of”, you’d need another image with the reversed spatial arrangement. Unless these contrasts are present, the loss provides no incentive to learn relational structure. And while very large batches (32k+ or 1M) help, they still don’t reliably cover all the compositional variations that matter. This limitation is highlighted in When and why vision-language models behave like bags-of-words, and what to do about it? (2022).
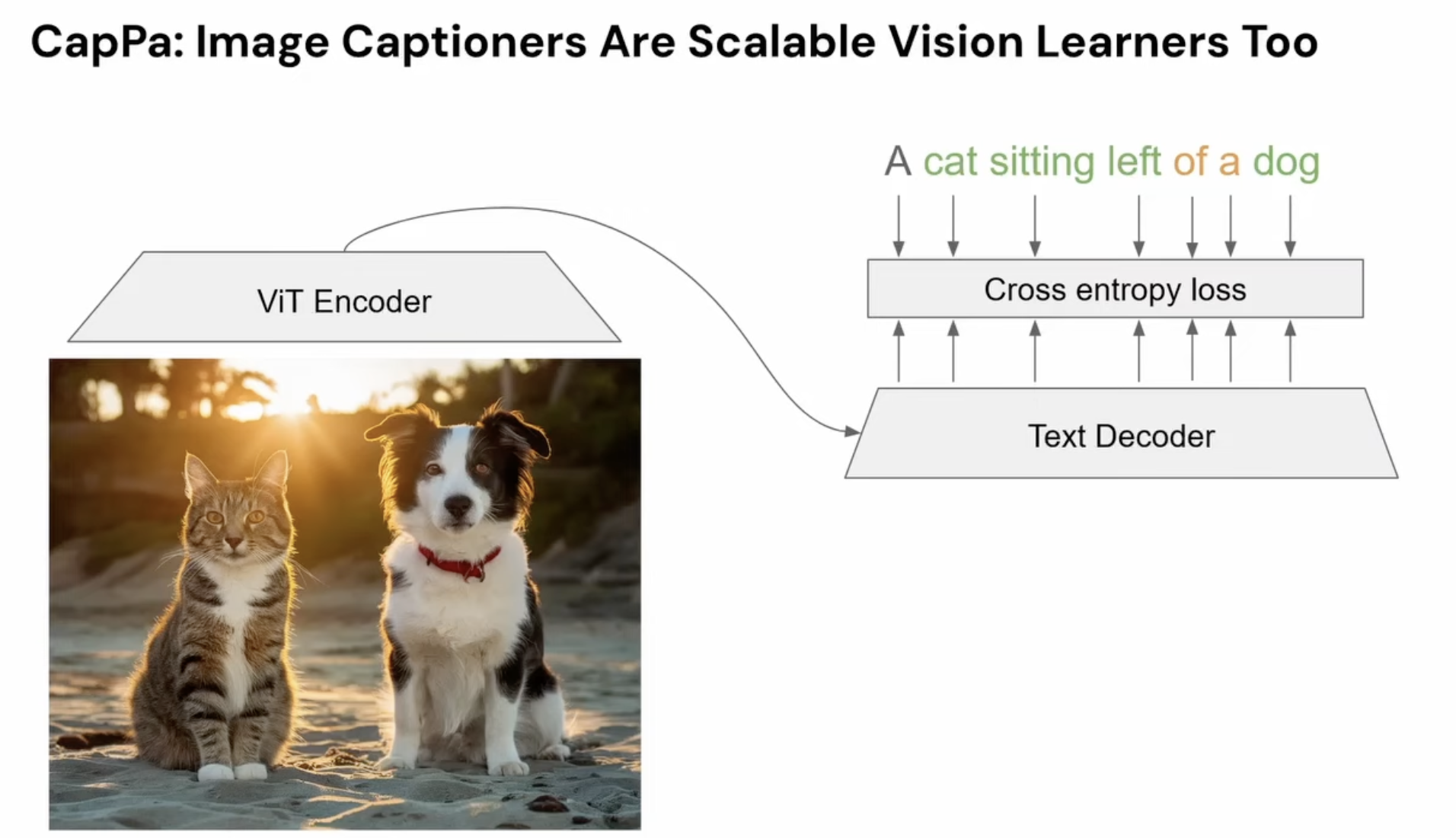
A different approach is to pre-train with a captioning task instead of a contrastive task. In captioning, the model generates the caption autoregressively, forcing it to model the entire sentence rather than just the discriminative parts. This provides a direct incentive to learn relational and compositional structure. This idea is central to CapPa: Image Captioners Are Scalable Vision Learners Too (2023).
 Evaluating such models requires careful benchmarks. Many widely used benchmarks turned out to be hackable: text-only models, with no access to the image, could outperform state-of-the-art vision–langage systems. This is because the hard negatives were often generated with simple word swaps, producing captions that were implausible or ungrammatical. For example:
Evaluating such models requires careful benchmarks. Many widely used benchmarks turned out to be hackable: text-only models, with no access to the image, could outperform state-of-the-art vision–langage systems. This is because the hard negatives were often generated with simple word swaps, producing captions that were implausible or ungrammatical. For example:
While the caption "olives and grapes on a plate" is a sensical fluent caption, benchmarks often have non-plausible hard negatives like "olives and grapes inside a plate" or simply incomprehensible ones like "right has word another word. There is a words". (SugarCrepe, 2023)

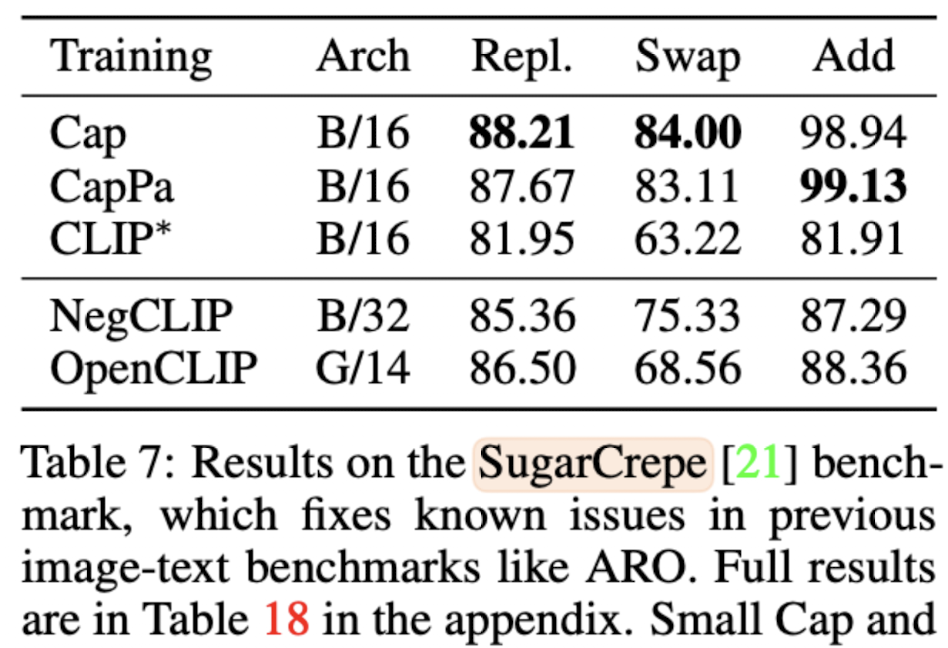
SugarCREPE fixes this by using LLMs to generate fluent and plausible hard negatives, followed by adversarial refinement to eliminate text-only shortcuts. On this benchmark, captioning-based models stand out: CapPa outperforms contrastive pre-training on fine-grained compositional tests:
As a result, the recommendation is that we should pre-train via captions and not by contrastive learning anymore.
PaLI and Multi-Stage Learning
The PaLI family (PaLI 2022; PaLI-X 2023 and PaliGemma 2024) represents the current paradigm of scaling vision–language models into general-purpose multimodal systems (similar to LLaVA 2023). These models essentially look like this:
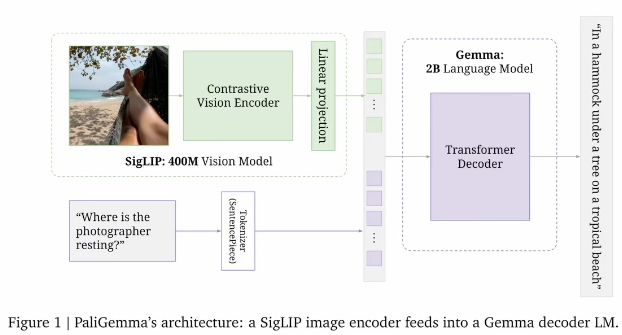 The result is a flexible setup that allows you to combine text and vision for many use cases. In this setting, only the output here needs masked attention; all of the inputs can have full attention; the question tokens can also look at the image tokens and vice versa.
The result is a flexible setup that allows you to combine text and vision for many use cases. In this setting, only the output here needs masked attention; all of the inputs can have full attention; the question tokens can also look at the image tokens and vice versa.
 These models are trained in four stages, well described in the Pali-Gemma paper.
These models are trained in four stages, well described in the Pali-Gemma paper.
- Stage 0: Unimodal pre-training - start with strong off-the-shelf language and vision encoders. Pali-Gemma uses SigLIP as the vision encoder, and Gemma-2B as the decoder-only language model.
- Stage 1: Multimodal pre-training - train the full model on a mixture of image–text tasks. In Pali-Gemma's case, nothing is frozen. This is contrary to earlier works such as LiT (2021), which showed that fine-tuning a pre-trained image encoder on noisy image–text data can actually degrade its general representations, which is why freezing the vision encoder worked best. PaliGemma acknowledges this challenge but works around it by using a linear warm-up on the vision encoder’s learning rate, allowing it to adapt without destroying its pre-trained quality.
- Stage 2: Resolution increase. Resume pre-training at higher image resolution. Pali-Gemma increases the resolution from 224x224 to 448x448 and then to 896x896. This does two things simultaneously: it makes fine details visible (important for tasks like OCR), and it lengthens the token sequence which results in more FLOPs and capacity. Both are useful, as shown in paper's ablations where the model is trained on a higher resolution, but then tested on the lower resolution again.
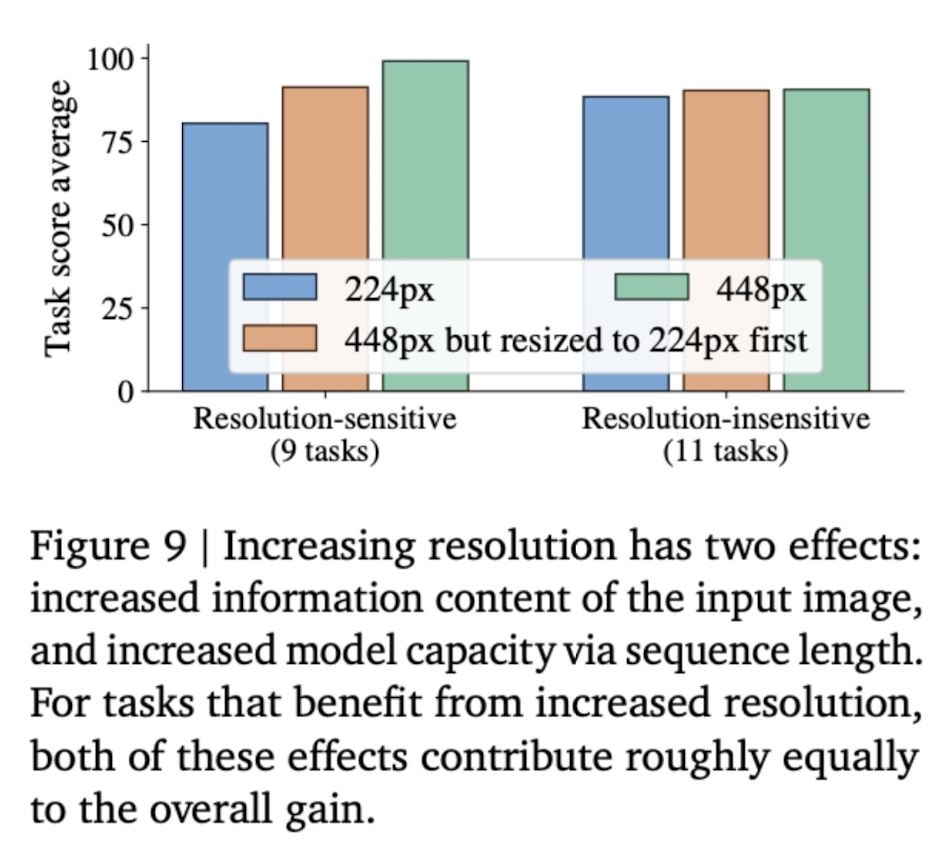
- Stage 3: Transfer / specialisation. Finally, adapt the base model to task-specific domains. Here, we can fine-tune the model on specific tasks to get even better performance.
Pre-training data
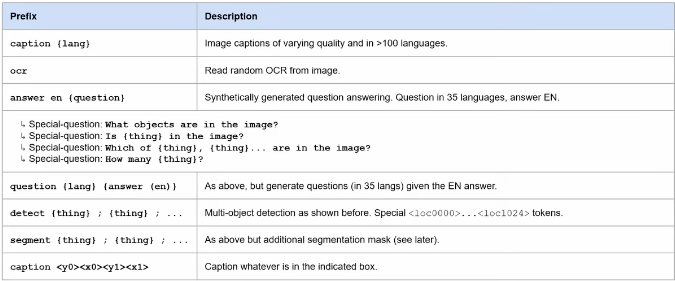
The pre-training data mixture contains a broad set of tasks:
Two caveats follow from this design. First, web-scale mixtures give the model “skills”
aligned to what is abundant online. Domains with little web presence (e.g. medical
imaging) see almost no benefit from multimodal pre-training, as highlighted in the
paper: 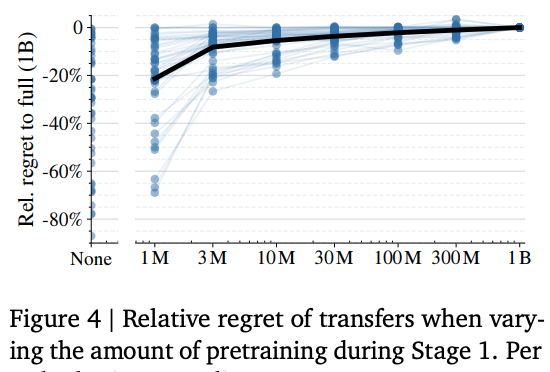 In the plot above, each dot represents a task, and there are tasks that do not degrade
in performance with no pre-training (top-left dots). Second, because the dataset
design is important to obtain a good model performance, much current progress in
VLMs comes from creative dataset generation and re-weighting rather than architectural
novelty. Modern VLMs can learn almost anything given the right data.
In the plot above, each dot represents a task, and there are tasks that do not degrade
in performance with no pre-training (top-left dots). Second, because the dataset
design is important to obtain a good model performance, much current progress in
VLMs comes from creative dataset generation and re-weighting rather than architectural
novelty. Modern VLMs can learn almost anything given the right data.
Computer vision tasks with VLMs
So far, we mostly discussed captioning and CLIP-like tasks. But modern VLMs can learn much more, given the right setup. They can also perform well on traditional computer vision tasks such as object detection or segmentation.
Pix2Seq (2021) was an early demonstration of this idea. For bounding box prediction, it discretises box-coordinates and encodes them as text, which are then predicted in a standard autoregressive way. And this works well!
 Segmentation seems harder. A panoptic segmentation map requires assigning an object ID to every pixel, which would create a huge output space (millions of tokens) if done in a standard auto-regressive way. Simply discretising the (panoptic) segmentation as tokens does not work well. UViM (2022) and related work propose a solution by introducing a discrete vocabulary, learnt with a VQ-VAE (2017). The training consists of two stages:
Segmentation seems harder. A panoptic segmentation map requires assigning an object ID to every pixel, which would create a huge output space (millions of tokens) if done in a standard auto-regressive way. Simply discretising the (panoptic) segmentation as tokens does not work well. UViM (2022) and related work propose a solution by introducing a discrete vocabulary, learnt with a VQ-VAE (2017). The training consists of two stages:
- A VQ-VAE learns to model the segmentation map, and its discrete bottleneck embedding can then be seen as a compressed version of this segmentation, containing useful information about the segmentation. The encoder (called oracle ) only has acces to the ground truth, the decoder (called base model ) to the original input image and the embedding learnt by the encoder.
- Now, at inference time we can of course not use the ground truth segmentation map. But given that our bottleneck is discrete, we can learn it with a separate model in a standard LLM-like autoregressive way, with the difference that here we take as input our input image.
See the original VQ-VAE paper or numerous (1, 2, 3) short video explanations to get an intuition of how the VQ-VAE setup can produce discrete tokens.
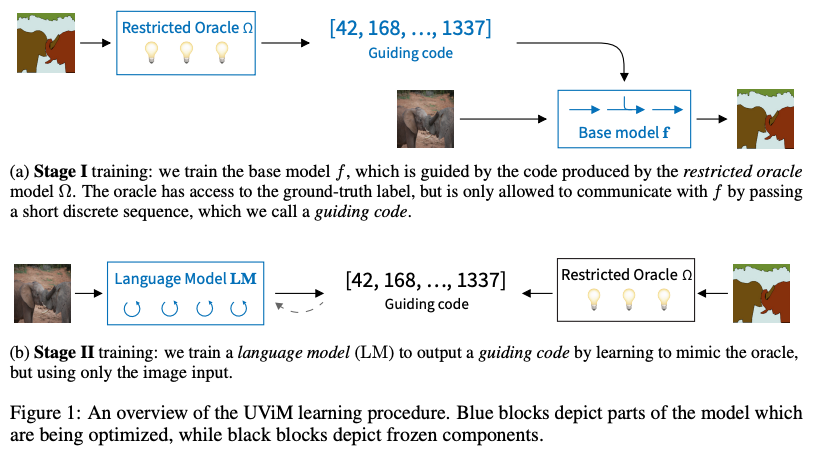
Given now our autoregressive model that learnt to produce the bottleneck, at inference time we use that model to produce the bottleneck, and then feed it with the input image to the base model to produce our segmentation map. So, at inference time, with input we have and then to get to our output . At a high-level, we now have again a standard VLM setup that can produce tokens that are useful for segmentation, although we still need a separate base model to get to the output.
We end this section with the following quote from the presentation:
VQ-VAEs are a great tool, if you can make them work. Most uses are full of 'tricks' to make them work. Improving this state is a new, very active area of research.
Reinforcement learning and vision-language models
Training vision–language models with autoregressive next-token prediction is, at its core, imitation learning. The model learns to reproduce tokens from its dataset, whether those are words in a caption or quantized codes for a segmentation mask. This works well, but it introduces a mismatch: the training objective may not align with what we actually care about.
Take bounding boxes as an example. If the ground-truth coordinate is 500, standard cross-entropy treats 501 as completely wrong. In practice, those two boxes are indistinguishable for most downstream uses. So our standard cross-entropy loss is not exactly what we want: it rewards exact reproduction and does not reflect the task quality. This is where reinforcement learning comes in.
In the RL setting, we can design our reward such that we can provide more precise signal to our model. For example, we can assign a reward based on Intersection over Union which is more standard for bounding box prediction. In standard reinforcement learning, we sample multiple candidate outputs from the model and incentivise the model to increase the likelihood of higher-scoring outputs, and suppress lower ones. Given that we now have a language model that determines our output, we can easily sample a distribution of outputs (e.g. with a different temperature, top-k or top-p sampling) and then evaluate them. As a result, we have a more precise loss.
Example: Tuning computer vision models with task rewards (2023).

Vision and language are converging
From the above, we see that vision tasks are increasingly reframed as token prediction under autoregressive objectives. The central challenge in computer vision is no longer architectural design, but the reformulation of tasks into datasets amenable to VLM training. Once expressed in this way, strong pre-trained components (e.g. SigLIP, Gemma) combined with a general transformer architecture results in competitive performance across a wide range of tasks.
References
- Learning Transferable Visual Models From Natural Language Supervision (CLIP, 2021)
- Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision (ALIGN, 2021)
- Sigmoid Loss for Language Image Pre-Training (SigLIP, 2023)
- SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features (SigLIP 2, 2025)
- Image Captioners Are Scalable Vision Learners Too (CapPa, 2023)
- When and why vision-language models behave like bags-of-words, and what to do about it? (ARO, 2022)
- SugarCrepe: Fixing Hackable Benchmarks for Vision-Language Compositionality (SugarCrepe, 2023)
- PaLI: A Jointly-Scaled Multilingual Language-Image Model (PaLI, 2022)
- PaLI-X: On Scaling up a Multilingual Vision and Language Model (PaLI-X, 2023)
- PaliGemma: A versatile 3B VLM for transfer (PaliGemma, 2024)
- Pix2seq: A Language Modeling Framework for Object Detection (Pix2seq, 2021)
- UViM: A Unified Modeling Approach for Vision with Learned Guiding Codes (UViM, 2022)
- Neural Discrete Representation Learning (VQ-VAE, 2017)
- Tuning computer vision models with task rewards (Task RL for VLMs, 2023)