Scaling RL for Long Code Sequences
Reinforcement learning is hot. David Silver and Richard Sutton recently published The Era Of Experience, in which they argue that a new generation of agents will soon interact with the world not just through static human-generated data, but by learning continuously from their own experience. Their theory is that in doing so, RL models should be able to discover new theories, solutions, and scientific insights. In this blog post I want to take a step back and look at how RL is currently applied in one of the areas where model capabilities are rapidly improving: coding. I'll ignore most of the history of RL for coding LLMs, which may be the subject of another blog post. Here, I would like to focus on how current methods deal with the fact that coding instructions, and as a result the length of the output, increase with the increase in code task complexity. This should help to better hypothesise about how applying similar RL techniques to other domains might work.
Apologies for the use of some jargon. RL has many technical terms that might be daunting at first. Don't panic - understanding the basics is not so difficult, although fully grasping every aspect of it is more complicated.
RL, super high-level
The standard optimisation technique used for RL is Proximal Policy Optimisation. To understand PPO, we have to start by looking at REINFORCE, a simpler algorithm on which PPO builds. I can't do that better than Karpathy: see this blog post. From there on, for now, just assume that PPO is a variant of REINFORCE, mainly aimed at taming RL by restricting model parameter updates (I'm simplifying a lot here, but explaining RL properly is probably done better by others; I want to get to RL for coding).
For this blog post, remember the following: Policy-learning is variant of RL that tries to estimate a policy that leads to a positive reward given a certain state and an action we can take given the state. In coding RL, we have the following variables:
- Our policy is our language model; it determines what we do (hence the name policy)
- Our state is the sequence of tokens the model outputs.
- The action is the next token we predict.
- The reward can be defined in multiple ways. Think of it as something (another model, compiler feedback, unit tests, etc.) that determines if the code we wrote works.
The high-level idea is that after outputting many tokens, we have code that we can try to run, and running this code gives us feedback that tells us something about our tokens - were they, together, producing something meaningful? Based on this feedback (reward), we can update our model (policy). This verifiable reward that we can get with RL on code is actually quite amazing -- not many other domains have this as clearly as code.
RL for coding models
Now, how do we best employ RL in a coding environment? Let's look at two approaches. I'll specifically focus on challenges that occur once the task we're asking the model to do becomes more complex.
Applying RL to LLMs to generate code has actually been done for quite some time. For example, Chen et al. discuss execution-guided program synthesis in 2018 to generate Karel code. Later on, papers start introducing compiler and unit test feedback.
StepCoder
StepCoder (February 2024) is a nice paper to start with as it clearly explains some of the challenges of applying RL to code LLMs. We have to deal with the following:
- Lengthy code makes RL exploration difficult
- Unit tests may not cover all sections of our generated code; which means we might give rewards for irrelevant/erroneous code Let's unpack.
Our model is optimised when it receives a positive reward, for example, by generating code that passes a unit test. This makes the model more likely to generate similar tokens in similar contexts in the future. Now, if we ask our model a simple question, the code generated might be relatively short; and most generated tokens will have attributed to receiving the reward. However, the more we ask models to do complicated tasks, the longer their output will be. In long code sequences, the reward is sparse and delayed, given only after the entire program is generated and tested. As a result, it becomes difficult to accidentally stumble upon a good generation; a lot of code needs to be correct to get a positive reward. And this makes exploration and learning more difficult; it's more difficult to determine when our generation process produces something meaningful.
The second problem in a setting where a model produces a lot of code to solve a problem is that unit tests might not cover all of the generated code. More specifically, only a subset of the generated code might contribute to a passing unit test. However, a single reward is assigned to the entire trajectory; all generated tokens. This is problematic as standard RL techniques have no way to assign rewards to only a subsection of relevant code. As a result, useless code might be reinforced, which is ultimately not good for the performance of the model. We call this problem the reward assignment problem.
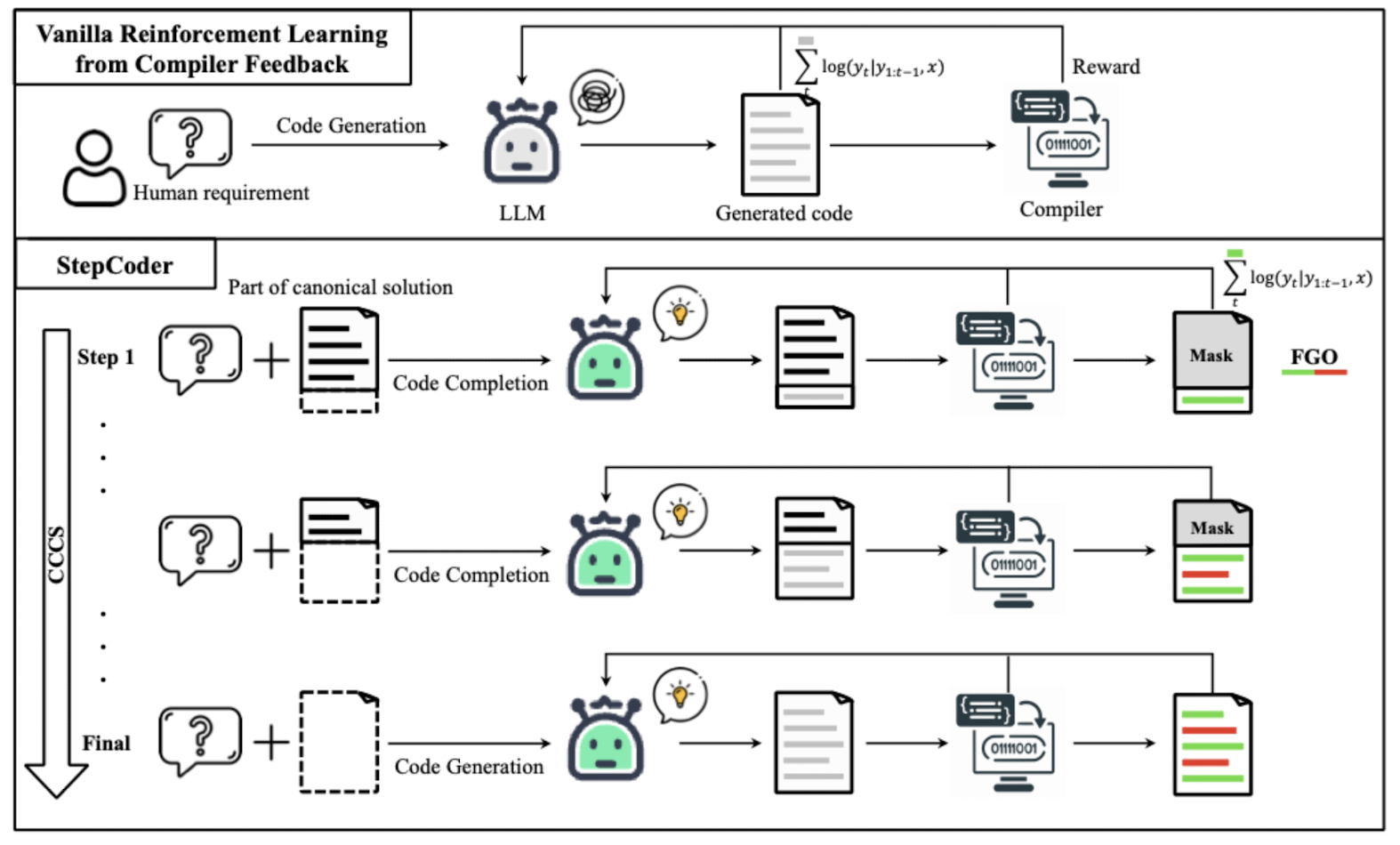
Curriculum learning
To fix these problems, StepCoder introduces two concepts: Curriculum of Code Completion Subtasks (CCCS) and Fine-grained Optimisation (FGO). CCCS is based on the following key idea: instead of learning to generate an entire program from scratch immediately, the model first learns to complete only the tail end of a known correct program, then progressively handles larger parts of the solution as it improves. Note that this requires the solution to be known. Specifically, we break down the solution into subtasks by analysing the abstract syntax tree (AST) and extracting the conditional statements. This gives us the following dataset , where:
- is the problem description (natural language)
- is the canonical solution code
- are the unit tests
- is the list of conditional statements extracted via AST Then, during training, we append a part of the solution up until to our input () and ask the model to generate the rest. We assign rewards as follows: To avoid learning based on our extended input, the part of the solution that is given in our input is masked during gradient computation. Once the moving average pass rate of this step exceeds a certain threshold, we move back and repeat the process, up until the point where we ask the model to complete the full solution without adding any hints to the input. The result of this setup is that the model is now able to explore each part of the solution without having to generate a long sequence that will likely not receive any reward.
Fine-grained Optimisation
Now, let's address the second problem; the reward assignment problem. When we assign a reward based on unit tests, the feedback from the compiler relates only to the code snippets that we execute. However, in a vanilla RL optimisation process, all generated tokens are part of the computation of the gradient to update our model. This is imprecise when some part of the generated solution contribute nothing to the unit test passing; it can lead to irrelevant tokens being reinforced despite contributing nothing to the outcome. To fix this, StepCoder proposes to mask tokens that are not executed in unit tests when computing the loss for updating the model. This is done by checking which part of the code is executed during a unit test; similar to how code coverage tests figure out which part of the code is covered in a test.
Together with CCCS, the algorithm is as follows:
 StepCoder leads to consistent improvements of a few percentage points across multiple code generation benchmarks. While the gains over prior RL baselines are modest in absolute terms (2–4% pass@1), conceptually I like the idea of finding ways to a) break down the solution into smaller components and b) only reward tokens contributing to the solution.
StepCoder leads to consistent improvements of a few percentage points across multiple code generation benchmarks. While the gains over prior RL baselines are modest in absolute terms (2–4% pass@1), conceptually I like the idea of finding ways to a) break down the solution into smaller components and b) only reward tokens contributing to the solution.
Using compiler feedback for reward modelling
DeepSeek-Coder-V2 (June 2024), takes a different approach to the credit assignment problem. Instead of training directly on the noisy 0-1 compiler feedback, they still train a separate reward model to provide the rewards during RL (GRPO) training. They mention that this improves robustness and generalisation ability compared to raw compiler signal and clearly show this in an ablation:
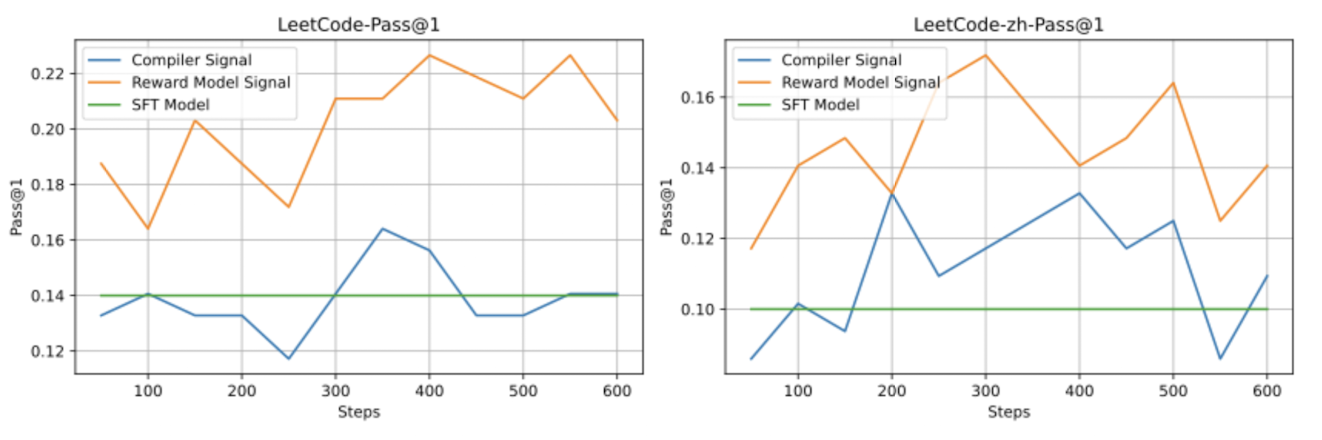 As with other methods, DeepSeek tends to find simpler methods that outperform more complicated, 'smart' methods. Although, one could argue as well that the signal directly from a compiler or unit test is cleaner, simpler; more direct, although noisy. Training a reward model, although common practice, is not an afterthought at all.
As with other methods, DeepSeek tends to find simpler methods that outperform more complicated, 'smart' methods. Although, one could argue as well that the signal directly from a compiler or unit test is cleaner, simpler; more direct, although noisy. Training a reward model, although common practice, is not an afterthought at all.
The general reward modelling + GPRO method used by DeepSeek is explained in this YouTube video, starting at 30:54:
I'm unsure what the future here is -- I'd have to dive deeper in to the different methods available today and play more with RL and reward modelling to get a better understanding of the trade offs here. To be continued.
If you liked this blog post, feel free to share it or follow me on LinkedIn or Twitter.