Insights by browsing 28 VLM eval datasets
Last week, I created Loupy.ai, a website that allows you to easily browse 28 popular vision-language datasets. I built it because I could not find a good way to figure out what evaluation datasets look like. As the first step when training a neural net is to become one with the data (Karpathy), I hope that making it easier to browse eval datasets will help researchers propose better solutions. This post contains some of the things I learned by browsing the datasets.
The diversity of questions in the reviewed datasets is immense, from simple tasks that 3-year-olds can solve to trick questions that take you a few minutes to answer. Despite that, some axes (e.g. multilinguality, question types) remain underexplored, and although benchmarks have been getting better, there are still some shortcomings.
The datasets are selected based on the evaluation of Kimi 2.5 (February '26), augmented with a few additional popular VLM evaluation datasets. You can find all datasets here:
Language distribution
Let's start with some simple statistics. All datasets are either Chinese and/or English. Only one dataset has another language (Persian).
71,574 samples across 28 datasets
While the USA leads in dataset authorship, China is a close second. Yet, the benchmarks remain overwhelmingly English.
Note that this analysis is based on institutional affiliation, not researcher background. One positive note here is the fact that most of these datasets are published by university students/labs. Eval papers seem to be a great way to contribute to state-of-the-art research if you're in academia. And, speaking as someone who's only been working in industry, data work is really useful in industry as well, where being really familiar with your (eval) data is often more important for progress than the use of a specific architecture or optimiser.
Fortunately, most labs are aware of the lack of multilingual vision-language model evaluation datasets. For example, Qwen3-VL evaluates on a private multilingual OCR dataset:
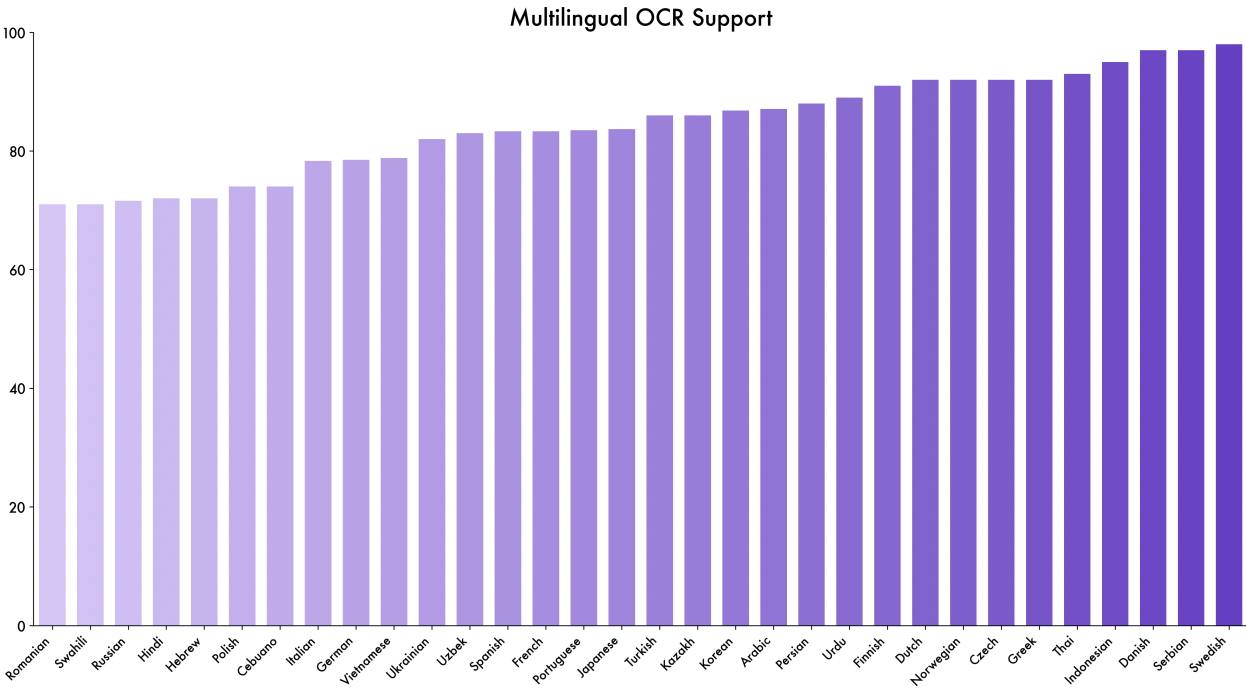
Figure 2 Qwen3-VL: Multilingual OCR performance of our model on a self-built test set. The model achieves over 70% accuracy on 32 out of 39 supported languages, demonstrating strong and usable multilingual capabilities.
A few multilingual VLM benchmarks were published over the past few years: CVQA, MTVQA, and EXAMS-V. However, these datasets are generally testing specific knowledge and don't yet have the breadth of, e.g. MMMU. xdocparse by dots.ocr looks promising, but so far, the dataset is not publicly available. I hope we will see more public efforts to create extensive multilingual VLM eval datasets in the coming years.
Diversity
Questions among the entire range of datasets are very diverse. Simple VQA questions exist, but the past few years, researchers have found more and more creative ways to prompt the VLM.
- MathVerse has 5 variants for each question, where progressively, more and more information is added to the image and removed from the question.
- BLINK uses two images, where image A has a reference point marked, and image B has four points A-D, where one is the reference point. The model has to predict which one is the reference point. The nice thing is that image A and B are not exactly similar but different views of the same scene.
- MMVP sources images by looking at similarity in CLIP space, and then asks questions about their difference.
- HallusionBench contains original and edited images that test if the model will hallucinate the wrong answer. Edited charts, images, and excerpts of famous speeches.
- BabyVision is a dataset of 22 different tasks that assess core vision tasks that children can solve, e.g. matching shapes to shadows, finding one different shape among other shapes, etc. The best models get only 50% correct.
These datasets vary across a wide set of axes: we can vary the evaluation sets by question difficulty calibrated to human age groups, assumed world knowledge, the balance between visual and textual reasoning, number of images, image perspectives, etc. We often take our human vision capabilities for granted, but precisely the diversity of visual tasks humans can perform well on makes it quite challenging to create comprehensive VLM eval sets.
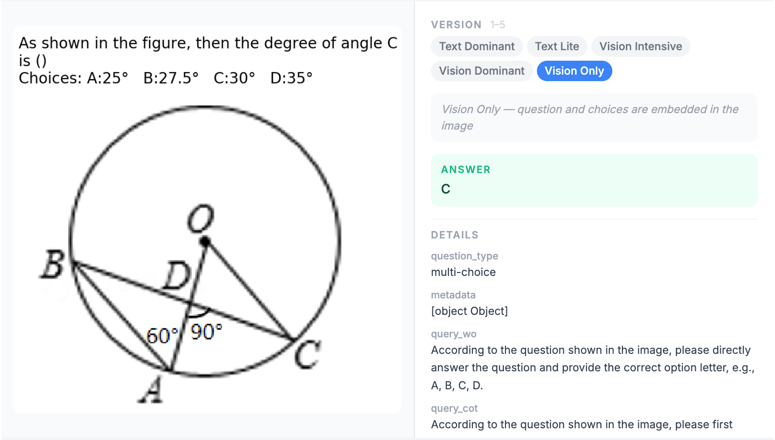
Dataset spotlights
Zerobench = visual AGI?
Zerobench (Loupy link) was a particularly fun dataset to review. Some of the questions in this dataset are incredibly difficult to answer. One example to indicate the difficulty:

Question: Examine the photo containing a collection of timepieces. Unless specified with a label, all analogue watches display the local time in Cambridge (UK), where it is currently a few days after the winter solstice. Interpreting the time on each timepiece to the nearest 5 minutes, by how many minutes does the Australian Eastern Daylight Time watch need to be moved back to display the correct time? (Link)
Realise what's needed to answer this question. I need to:
- Know the time difference between Australian Eastern Daylight Time and Cambridge (UK), a few days after the winter solstice (+11 hours).
- Read the time of the only unlabelled analogue watch (not the other analogue watch which is labelled, not the digital clock, not the digital Casio watch), which indicates the Cambridge time, and round to the nearest 5 minutes: 12:10.
- Now, we know that the correct time in Australian Eastern Daylight Time should be 12:10 + 11 hours = 23:10.
- Detect the watch labelled "Sydney".
- Realise I cannot read the time by looking at the watch itself - the hour indicator is hidden.
- Realise there's a mirror in the image, which reflects the watch, although it does not have the label.
- Now, realise we need to reverse the clock (which has no number indications, making this even more difficult!) to read the time.
- Read the time of the reversed watch: 7:15.
- Calculate the difference from 23:10 to 07:15 = 8 hours and 5 minutes = 485 minutes ahead.
Prompting Opus 4.6 with this puzzle without any special scaffolding didn't lead to a good answer - it thought the digital watch was labelled "Sydney" and reasoned from there.
It also read the time in Cambridge as 12:00.
Solving ZeroBench might be pretty close to AGI-level vision-language reasoning.
Current SOTA models are at about 10% accuracy (the benchmark has just 100 questions, so they get about 10 questions correct). You might think these visual puzzles are 'artificial' or 'pointless', I disagree: a model that would solve a wide variety of these questions,
is probably pretty good at visual reasoning, and hence, this is a great benchmark.
There should be real-life benefits too. I imagine that a model that can directly count specific objects in an image, and reason from there, even when objects are partially hidden, is probably pretty useful in e.g. robotic applications.
I'm very curious to see what the performance will be on this dataset in 2027 or 2028.
BabyVision
BabyVision (Loupy link) is another fun dataset that has a unique angle. It contains 388 simple visual questions that young children can solve. The amazing thing is that the authors actually benchmarked this: They collected results from 3-, 6-, 10-, and 12-year-olds, 20 per group (albeit from a single school), giving them 45 minutes to complete 20 questions. Then they compared these results with those of state-of-the-art VLMs. The results are striking:
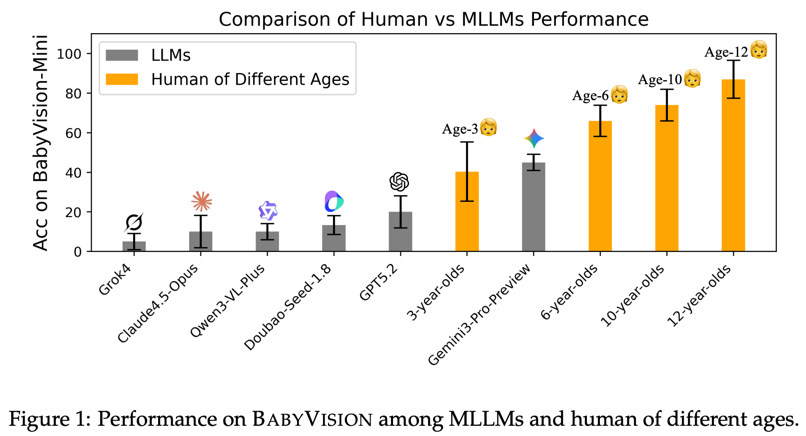
Most frontier MLLMs perform well below the average 3-year-old, despite their PhD-level results on language benchmarks. Gemini3-Pro-Preview is the notable outlier—the only model consistently above the Age-3 band—yet it still lags typical 6-year-olds by about 20 points.
Interesting as well that there's quite a difference in performance across models (Gemini-3-Pro scores 49.7%, whereas Opus scores only 14.2%). The authors attribute the poor performance of current VLMs to the 'verbalisation bottleneck', which they define as follows:
Current MLLMs process visual inputs by translating them into language representations before reasoning. While this approach leverages the powerful reasoning capabilities of large language models, it introduces a fundamental limitation: visual information that cannot be faithfully expressed in language is lost.
It'd be interesting to see papers explore this in more detail in the coming years - can we get better at vision problems by not relying on, or slightly changing the current standard paradigm of VLMs? DeepSeek-OCR 2 (Jan '26) can be seen as an initial stab at this problem. It aims to give the vision encoder its own causal reasoning capability so it can intelligently reorder visual tokens before they are fed into an LLM decoder. While the paper focuses only on OCR, ideas in this direction might help models perform better on BabyVision. There's still quite a lot of work to do to 'solve vision'!
VLM eval limitations
There have been many papers published in recent years on the limitations of VLM evaluations. The purpose of this blog post is not to provide a full literature review of these limitations - I'll mention a few that stand out.
One of the most common limitations mentioned in critiques is that questions can be answered without looking at the image. Some examples here:

(MMBench) What do hedgehogs do when they are scared? A) They shoot their spines like arrows. B) They curl up into a ball.
From my analysis, mostly somewhat older datasets have a 'blind solvability' problem. A few papers describe this limitation. The MMStar paper, Are We on the Right Way for Evaluating Large Vision-Language Models? (Neurips 2024), was the highest quality paper I could find on this issue. The paper reports that, for example, GeminiPro achieves 42.9% on the MMMU benchmark without any visual input. This motivates their work to create a new benchmark: MMStar (Loupy link). Among the datasets I currently include on the website, the top scores without image access reported in this paper are 42.9% for MMMU, 68.9% for ScienceQA, 59.7% for AI2D, and 24.2% for MathVista. Importantly, blind solvability has two flavours, described in the paper. First, some questions genuinely don't require access to the image to be answered. But there are also questions that do require access to the image, but can still be answered correctly by models. This hints at dataset leakage into the training data. The paper mentions that this leakage is usually unintended, as 'it’s impractical to predict which data will be used in future evaluation benchmarks during the preparation for the training corpus'. I'd be a bit more strict and say that if labs spend billions, there's an obligation to align pre-training corpus selection and evaluation datasets, particularly for popular datasets. I'm unsure how this currently works, but a reasonable baseline would be a script that flags any evaluation set available in the pre-training data, of which the results can then be presented to an eval team.
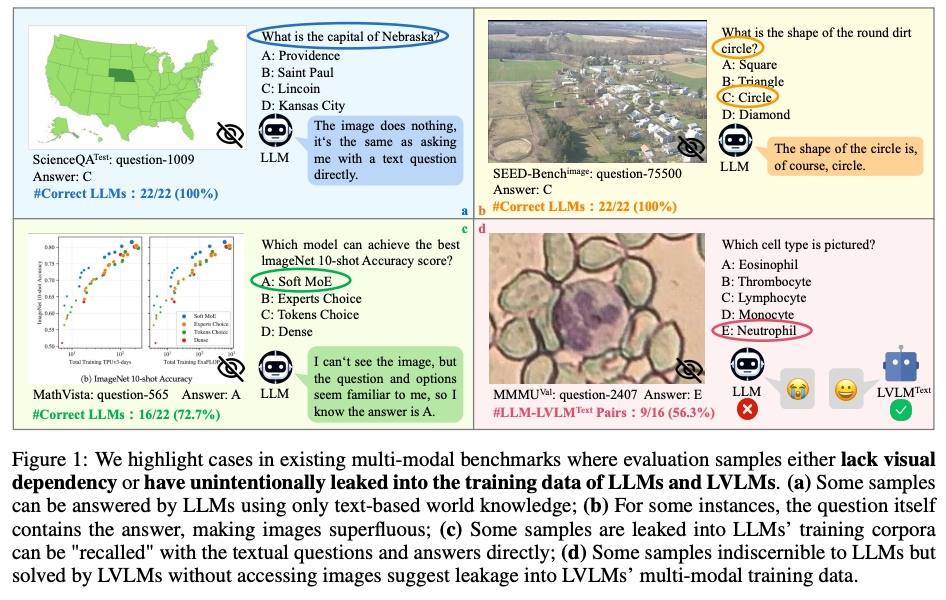
Question repetition
One additional shortcoming I noticed when reviewing the datasets is that not all datasets are incredibly varied on their own, and that not all questions align well with what the dataset is supposed to test. For example, 48/1000 MathVista questions are about the age gap between people in a photo. That's almost 5% of the dataset dedicated to a single question type. I see how this can be a decent world knowledge question, though - it requires detailed knowledge of somewhat famous people. However, I might not really call it 'mathematical' reasoning.

















































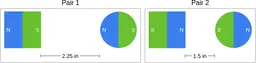
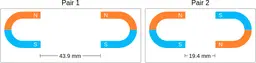
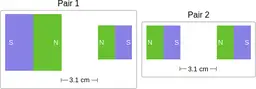
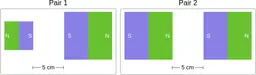
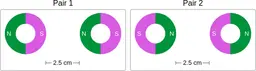
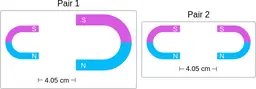
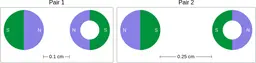
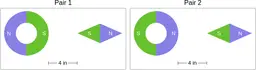
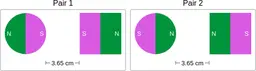
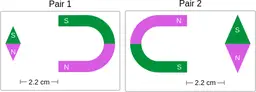
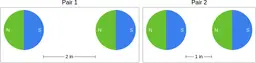
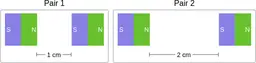
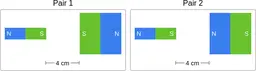
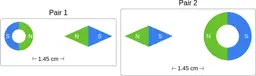
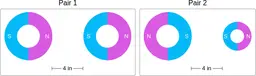
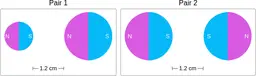
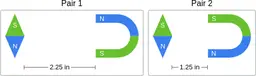
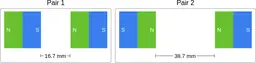
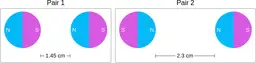
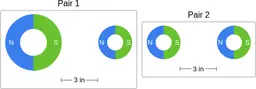
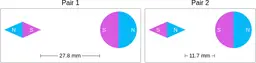
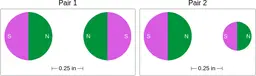
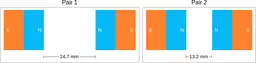
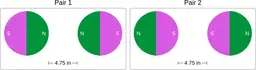
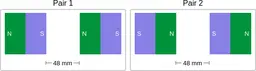
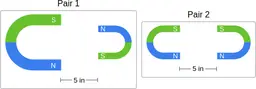
Similarly, ScienceQA has 120 out of 2,017 questions (6%) about comparing magnetic forces between pairs of magnets:
“Think about the magnetic force between the magnets in each pair. Which of the following statements is true?”
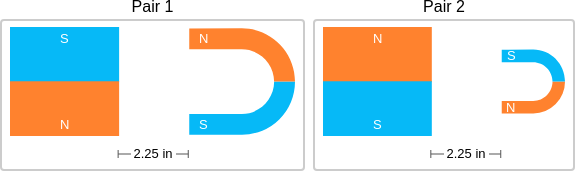 The magnitude of the magnetic force is smaller in Pair 2.
The magnitude of the magnetic force is smaller in Pair 2.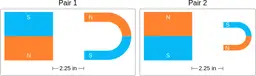










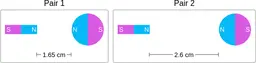
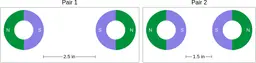



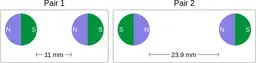

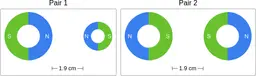









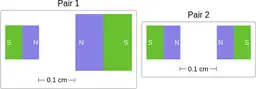
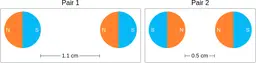

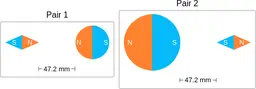





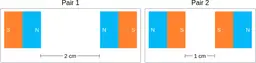



































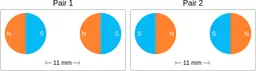


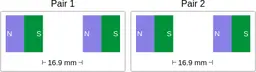

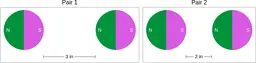

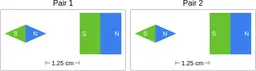
Despite these shortcomings, exploring these datasets was a fun exercise, and I was surprised by the ingenuity and diversity of the evaluation datasets. I hope you'll have fun browsing the datasets as well!
In my next post, I will present the evaluation results of these datasets.
Widgets written by Claude, text by myself :)Cite this post
@online{jochemgietema2026,
author = {Jochem Gietema},
title = {Insights by browsing 28 VLM eval datasets},
date = {2026-04-05},
url = {https://www.giete.ma/blog/vlm-eval-datasets},
urldate = {2026-04-05}
}